
【机器学习】Bert微调
参考:
代码:
一. 回顾Transformer
Transformer就是结合了自注意力机制的encoder-decoder网络。
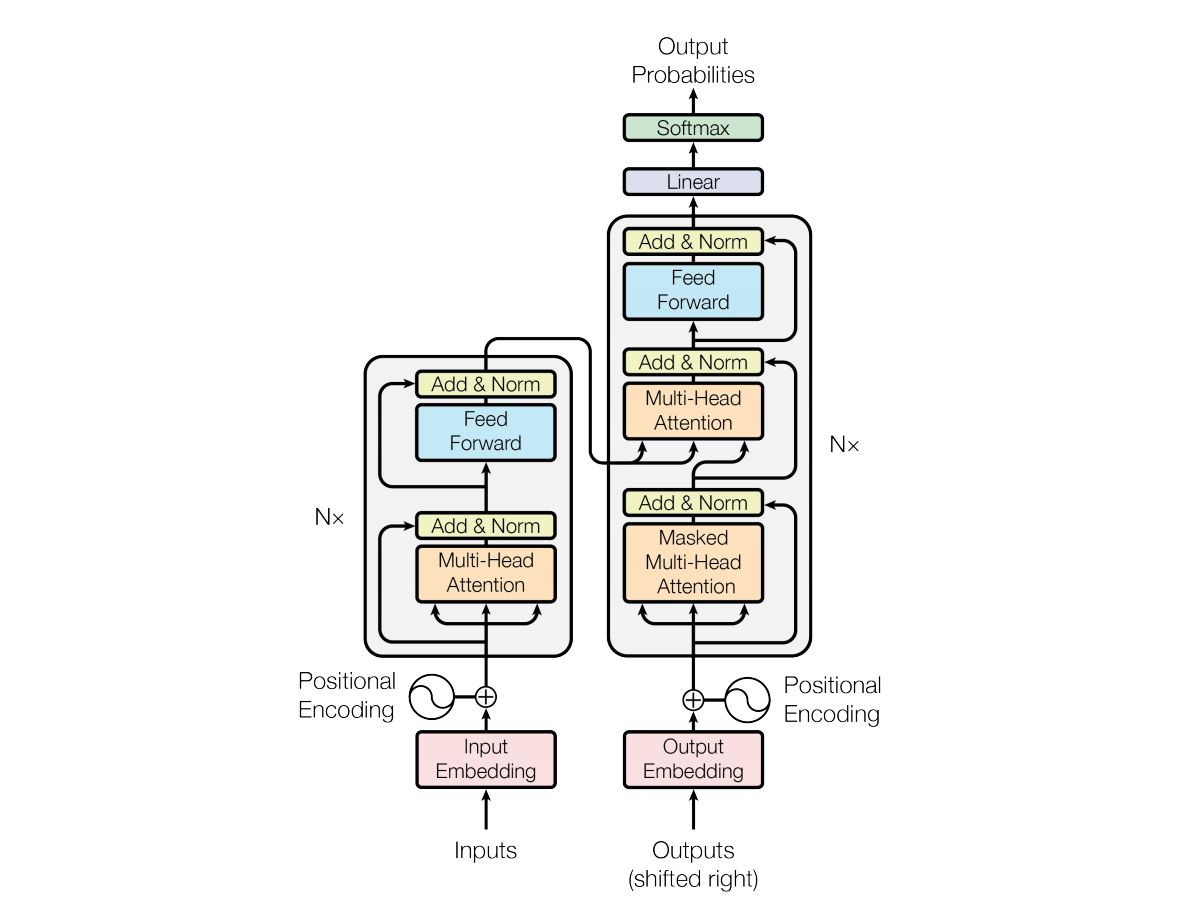
图的左边是Encoder右边是Decoder
二. BERT是什么有什么用
1.BERT的优点
在我们熟知的图像处理方向,模型微调的技术已经十分的成熟,我们CNN在学习过程中可以提取到一些深层特征和浅层特征,浅层的CNN网络往往学习到一些边缘,形状的很低级的特征,而深层网络可以学习到更加高级的特征,这些特征在许多图像处理问题中是通用的,所以可以载入预先训练好的模型权重,根据具体问题修改输出层进行再训练就可以取得比较好的效果。
在NLP领域的模型预训练和微调,就是采用的BERT,我们可以用特定的文本处理任务训练BERT,再将训练好的BERT模型进行魔改以适应不同的任务。
BERT有如下的特点:
采用MLM对双向的Transformers进行预训练,以生成深层的双向语言表征。
预训练后,只需要添加一个额外的输出层进行fine-tune,就可以在各种各样的下游任务中取得很好的表现。在这过程中并不需要对BERT进行任务特定的结构修改。
2. BERT与Transformer的联系
我们可能都知道BERT只采用了Transformer的Encoder部分,但实际上这样的说法很容易让人产生误解,让人以为BERT只是Transformer的缩小版而已,实际上BERT模型比是Transformer大几个数量级。
下图更加直观地展示了BERT与Transformer之间的关系。
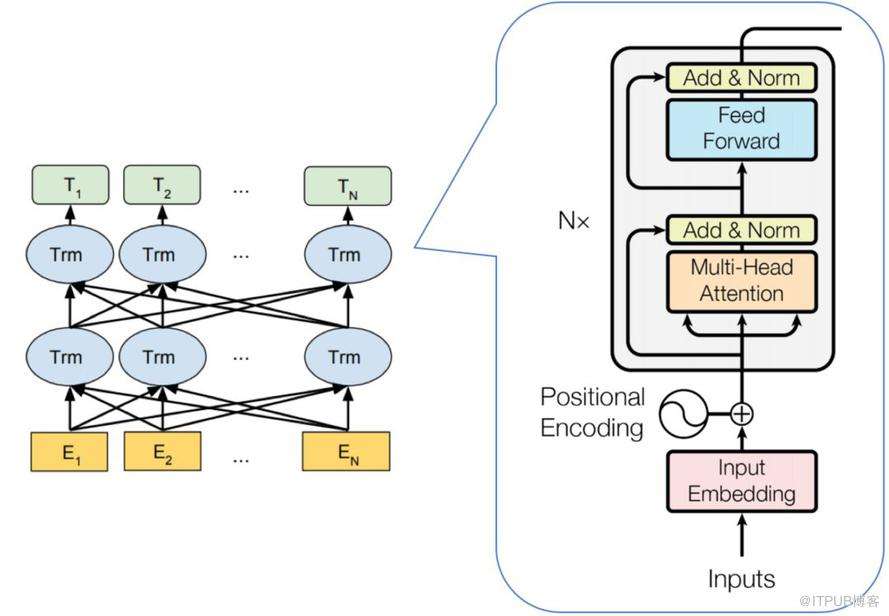
BERT将Transformer的编码器部分进行叠加。
论文中的BERT提供了简单和复杂两个模型,对应的超参数分别如下:
: L=12,H=768,A=12,参数总量110M;
: L=24,H=1024,A=16,参数总量340M;
在上面的超参数中,L表示网络的层数(即Transformer blocks的数量),A表示Multi-Head Attention中self-Attention的数量,filter的尺寸是4H。
三. BERT预训练
1. 关于自监督学习Self-supervised-learning
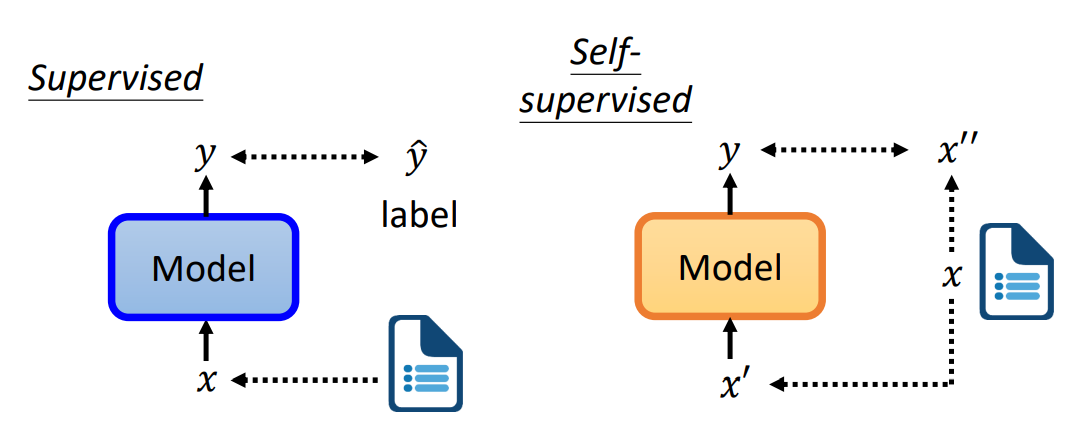
自监督学习与监督学习的区别在于标签并不是特意标注的,而是通过训练数据集自己产生的,而BERT可以看作是一种自监督学习模型,即BERT在进行与训练的时候所用的标签其实就是来自与文本数据自身。
具体是如何做到的呢?主要是通过两个预训练任务的设计来实现的,一个是MLM(Masked Language Model),另一个是NSP(Next Sentence Prediction),这个之后再解释。
2. BERT输入表示
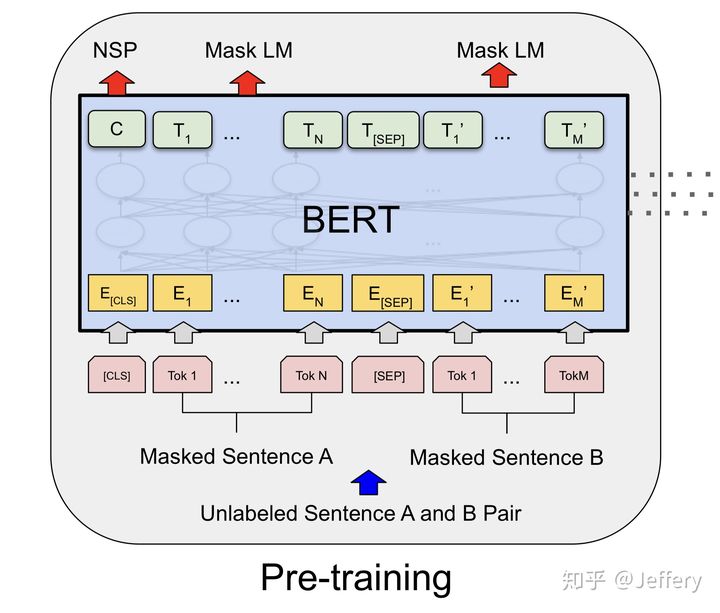
BERT的输入为每一个token对应的表征(图中的粉红色块就是token,黄色块就是token对应的表征),并且单词字典是采用WordPiece算法来进行构建的。
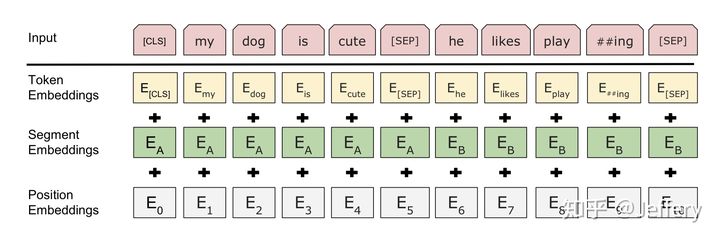
每一个token对应的表征组成一个编码向量(长度是512),该编码向量是3个嵌入特征的单位和,这三个词嵌入特征是:
WordPiece 嵌入:
WordPiece是指将单词划分成一组有限的公共子词单元,能在单词的有效性和字符的灵活性之间取得一个折中的平衡。例如将‘playing’被拆分成了‘play’和‘ing’;
位置嵌入(Position Embedding):
位置嵌入是指将单词的位置信息编码成特征向量,位置嵌入是向模型中引入单词位置关系的至关重要的一环。
位置嵌入其实就是一种代替位置编码的方法,当初讲自注意力机制的时候,使用的是不用带参数的位置编码,并且采用的是三角函数,为的是让输入数据带有位置信息,而BERT延续了这一思想,只不过将参数全部改成了可以学习的参数。
分割嵌入(Segment Embedding):用于区分两个句子,例如B是否是A的下文(对话场景,问答场景等)。对于句子对,第一个句子的特征值是0,第二个句子的特征值是1。
两个特殊符号[CLS]和[SEP],其中[CLS]表示该特征用于分类模型,对非分类模型,该符合可以省去。[SEP]表示分句符号,用于断开输入语料中的两个句子。
3. BERT预训练任务
3.1 Masked Language Model(MLM)
所谓MLM是指在训练的时候随即从输入预料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像完形填空。
mask的好处,即预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇( 10% 概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。
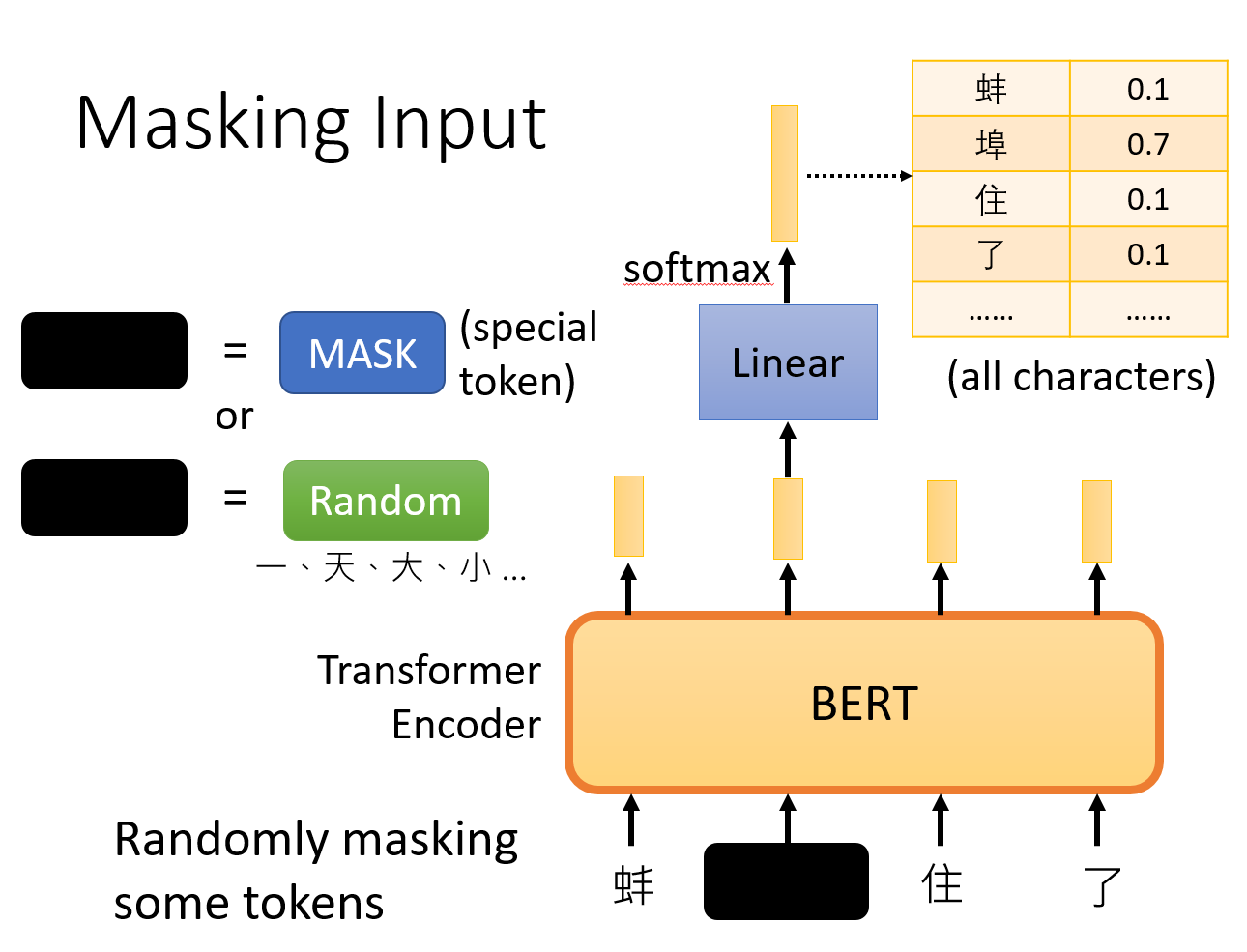
这个mask可以是特殊符号‘
在BERT的实验中,15%的WordPiece Token会被随机Mask掉。在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,80%的时候会直接替换为[Mask],10%的时候将其替换为其它任意单词,10%的时候会保留原始Token。
- 80%:
my dog is hairy -> my dog is [mask] - 10%:
my dog is hairy -> my dog is apple - 10%:
my dog is hairy -> my dog is hairy
这么做的原因是如果句子中的某个Token100%都会被mask掉,那么在fine-tuning的时候模型就会有一些没有见过的单词。加入随机Token的原因是因为Transformer要保持对每个输入token的分布式表征,否则模型就会记住这个[mask]是token ’hairy‘,但是实际fine-tune的时候并没有[mask]这个符号。至于随机单词带来的负面影响,因为一个单词被随机替换掉的概率只有15%*10% =1.5%,这个负面影响其实是可以忽略不计的。
3.2 Next Sentence Prediction(NSP)
为了帮助 理解两个⽂本序列之间的关系,BERT在预训练中考虑了⼀个⼆元分类任务——下⼀句预测。在为预训练⽣成 句⼦对时,有⼀半的时间它们确实是标签为“真”的连续句⼦;在另⼀半的时间⾥,第⼆个句⼦是从语料库 中随机抽取的,标记为“假”。
- 预测一个句子对中的两个句子是否相邻
- 训练样本中:
- 50%概率选择相邻句子对:
this movie is great i like it - 50%概率选择随机句子对:
this movie is great hello world - 将
对应的输出放到一个全连接层来预测
- 50%概率选择相邻句子对:
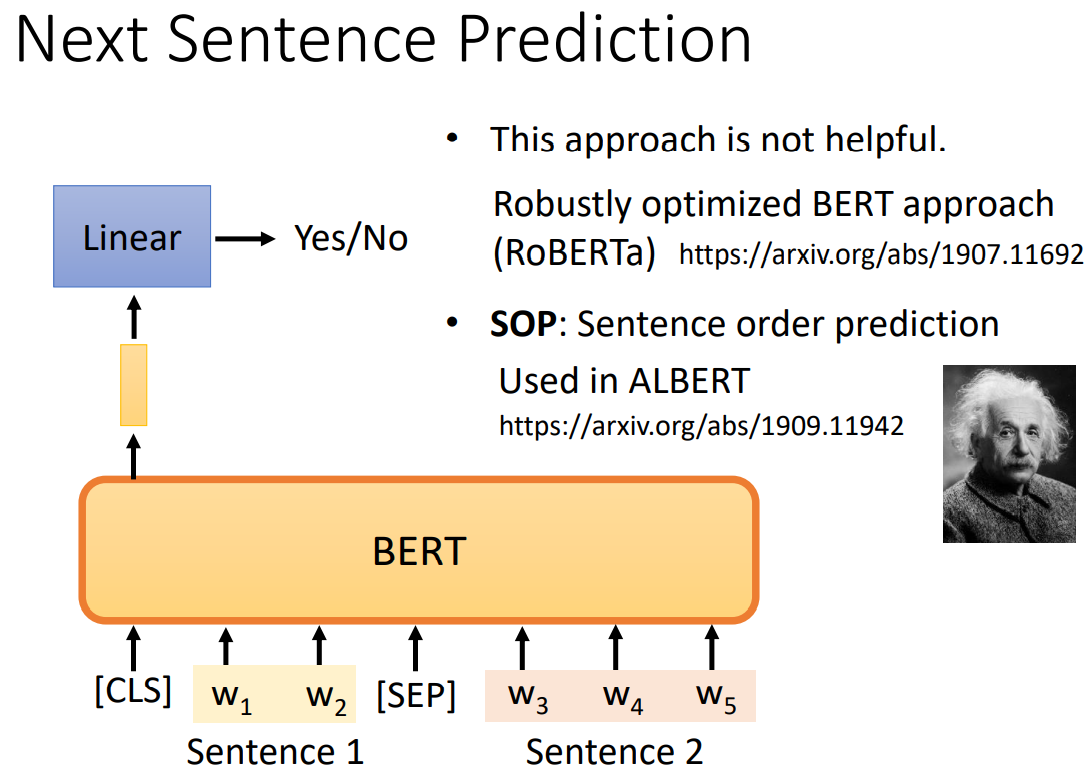
关于NSP是否有用是存在争议的,(参见RoBERTa这篇论文)。因为选定一个句子作为前一个句子,大部分情况下随机选到的句子都不是后一个句子,也就是BERT是很容易判断出来两个句子是否相邻的。对此也有人提出了改进方法SOP,SOP更加侧重于判断两个句子的前后关系,而不是两个句子是否相邻。
Tips: BERT预训练是多任务模型的预训练,因此NSP和MLM两个任务的训练是同时进行的。
四. BERT微调fine-tune
1. 自然语言推理(Natural Language Inference)
自然语言推理研究是否有假设可以从前提推断出来,其中两者都是文本序列。换句话说,自然语言推理决定了一对文本序列之间的逻辑关系。这种关系通常分为三种类型:
- 蕴含(entailment):假设可以从前提中推断出来。
- 矛盾(contradiction):可以从前提中推断假设的否定。
- 中立(neutral):所有其他情况。
自然语言推理也被称为识别文本蕴含任务。例如,下面的词元对将被标记为蕴含(entailment),因为假设中的 “显示亲情” 可以从前提中的 “相互拥抱” 推断出来。
前提:两个女人互相拥抱。
假设:两个女人表现出亲情。
以下是 矛盾 的例子,因为 “运行编码示例” 表示 “没有睡觉” 而不是 “睡觉”。
前提:一个男人正在运行从 “潜入深度学习” 中的编码示例。
假设:那个男人在睡觉。
第三个例子显示了 中立性 关系,因为 “正在为我们表演” 这一事实既不能推断 “著名的” 也不是 “不出名”。
前提:音乐家们正在为我们表演。
假设:音乐家很有名。
2. NLI微调模型
BERT在预训练好之后就可以通过更改输出层来完成不同的任务,本节所讲的fine-tune应用是自然语言推理Natural Language Inference
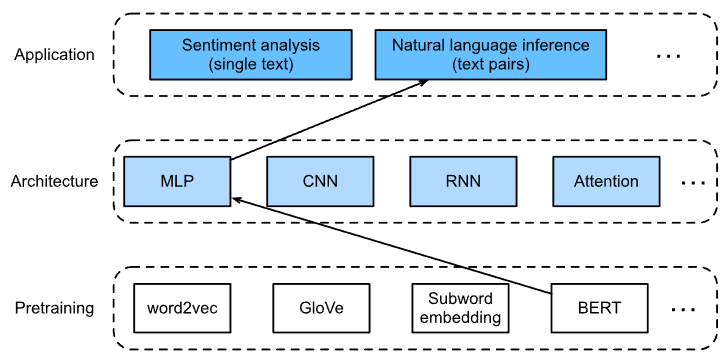
本次微调所用的输出层很简单,直接在BERT输出层添加一个多层感知机。
3. SNLI数据集
To Be Continued !










