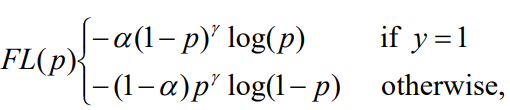【目标检测】YOLOv1-v3学习笔记
YOLOv1-v3学习笔记
1.YOLOv1
1.1 论文思想
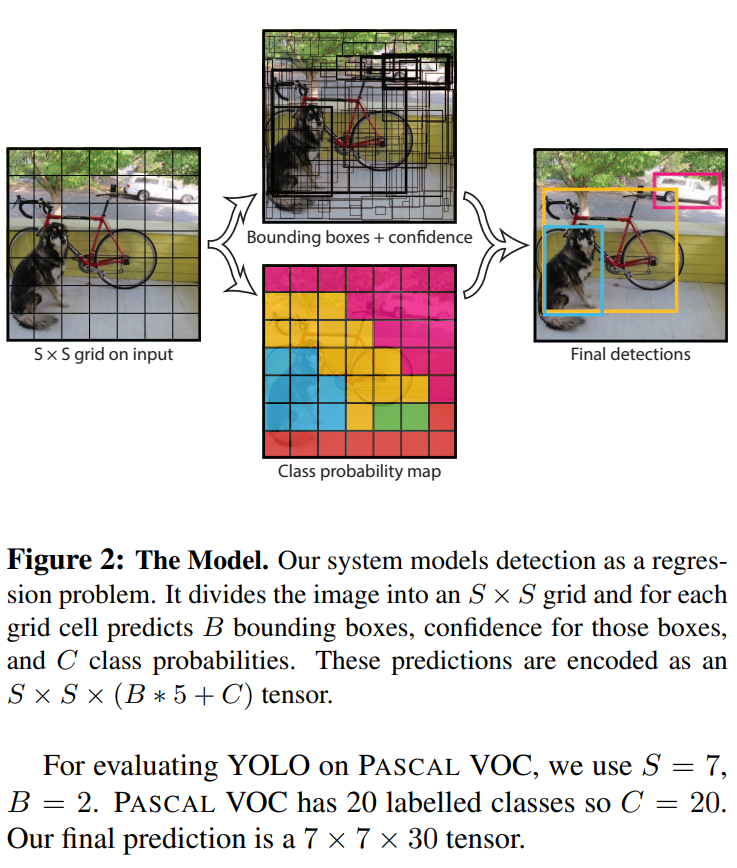
将一幅图像分成SxS个网格(grid cell), 如果某个object的中心 落在这个网格 中,则这个网格就负责预测这个object
每个网格要预测B个bounding box,每个bounding box 除了要预测位置之外,还要附带预测一个confidence值。每个网格还要预测C个类别的分数。
这个 confidence scores反映了模型对于这个栅格的预测:该栅格是否含有物体,以及这个box的坐标预测的有多准。公式定义如下:
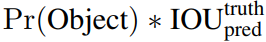
如果这个栅格中不存在一个object,则confidence score应该为0。否则的话,confidence score则为predicted bounding box与 ground truth box之间的 IOU。
YOLO对每个bounding box有5个predictions:x, y, w, h和 confidence。坐标x,y代表了预测的bounding box的中心与栅格边界的相对值。坐标w,h代表了预测的bounding box的width、height相对于整幅图像width,height的比例。confidence就是预测的bounding box和ground truth box的IOU值。
每一个栅格还要预测C个conditional class probability(条件类别概率):Pr(Classi|Object)。即在一个栅格包含一个Object的前提下,它属于某个类的概率。我们只为每个栅格预测一组(C个)类概率,而不考虑框B的数量。
在测试时,我们将条件类概率和单个框的置信预测相乘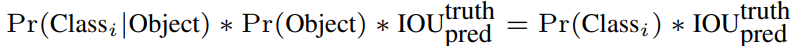
1.2 网络结构
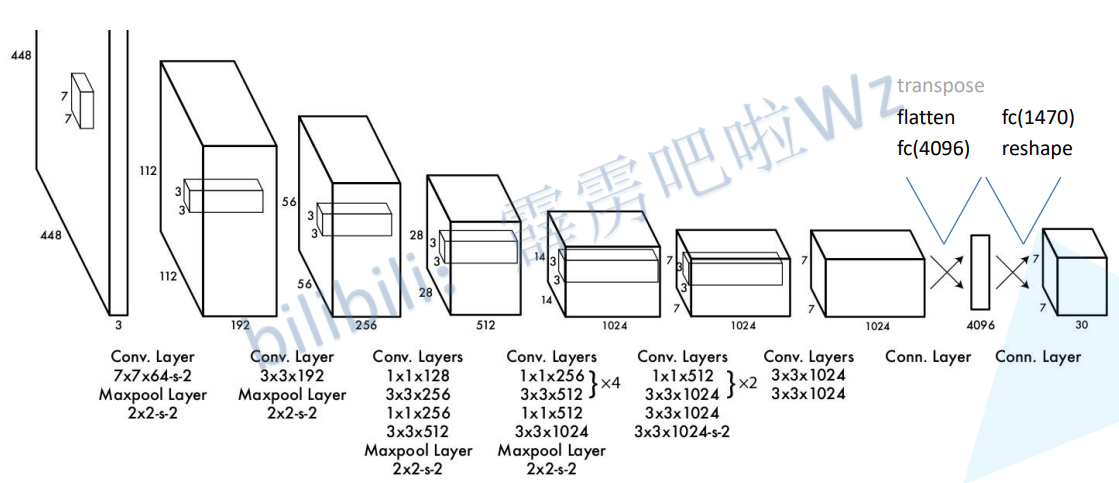
假设我们的cell数量设置成7x7,那么最后一定输出是一个7x7x30的立方体。
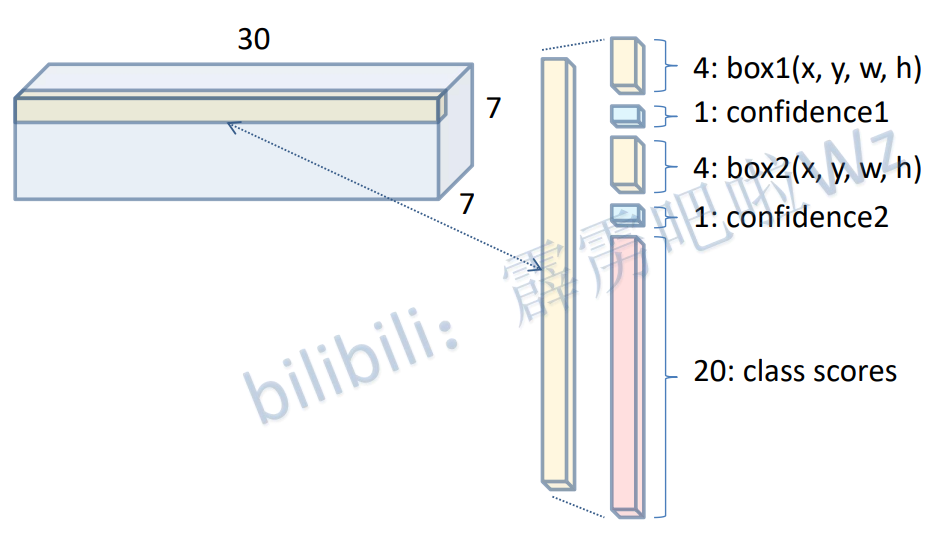
yolov1每个cell预测两个box,输出形状如下
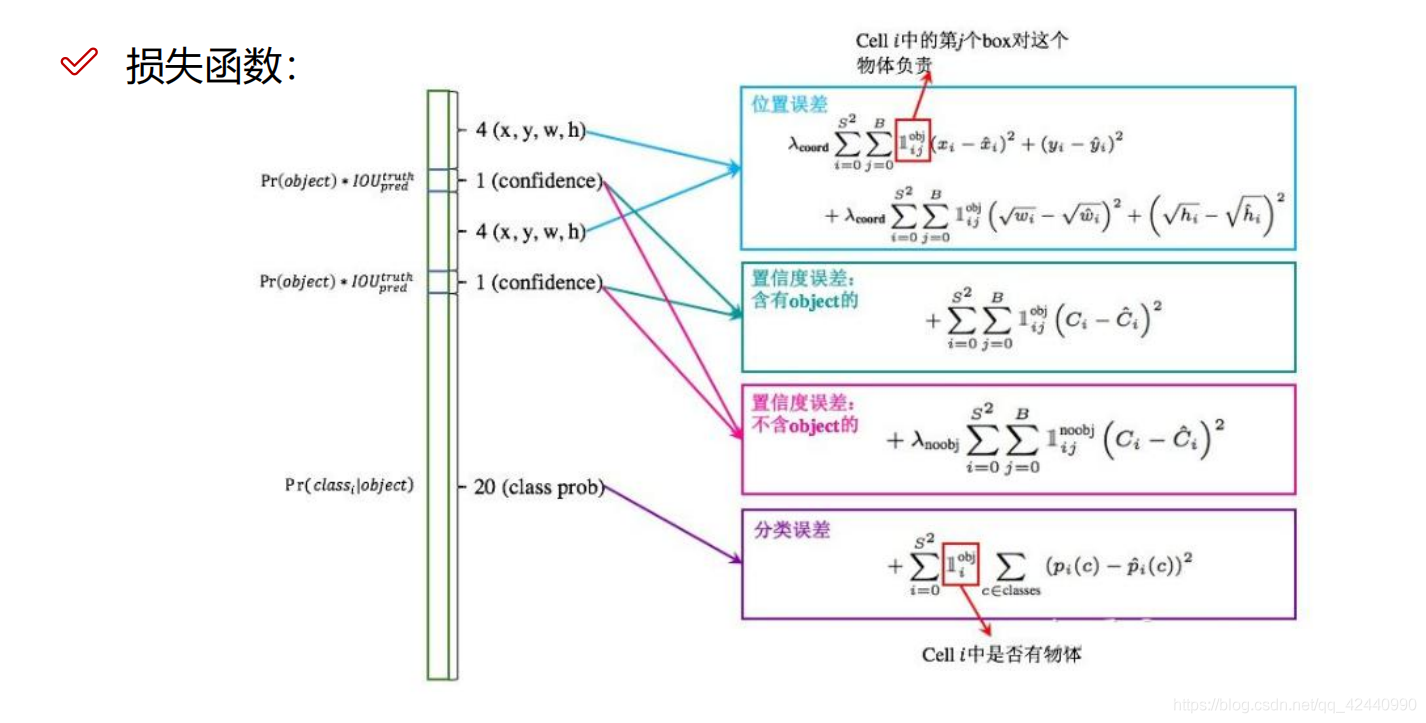
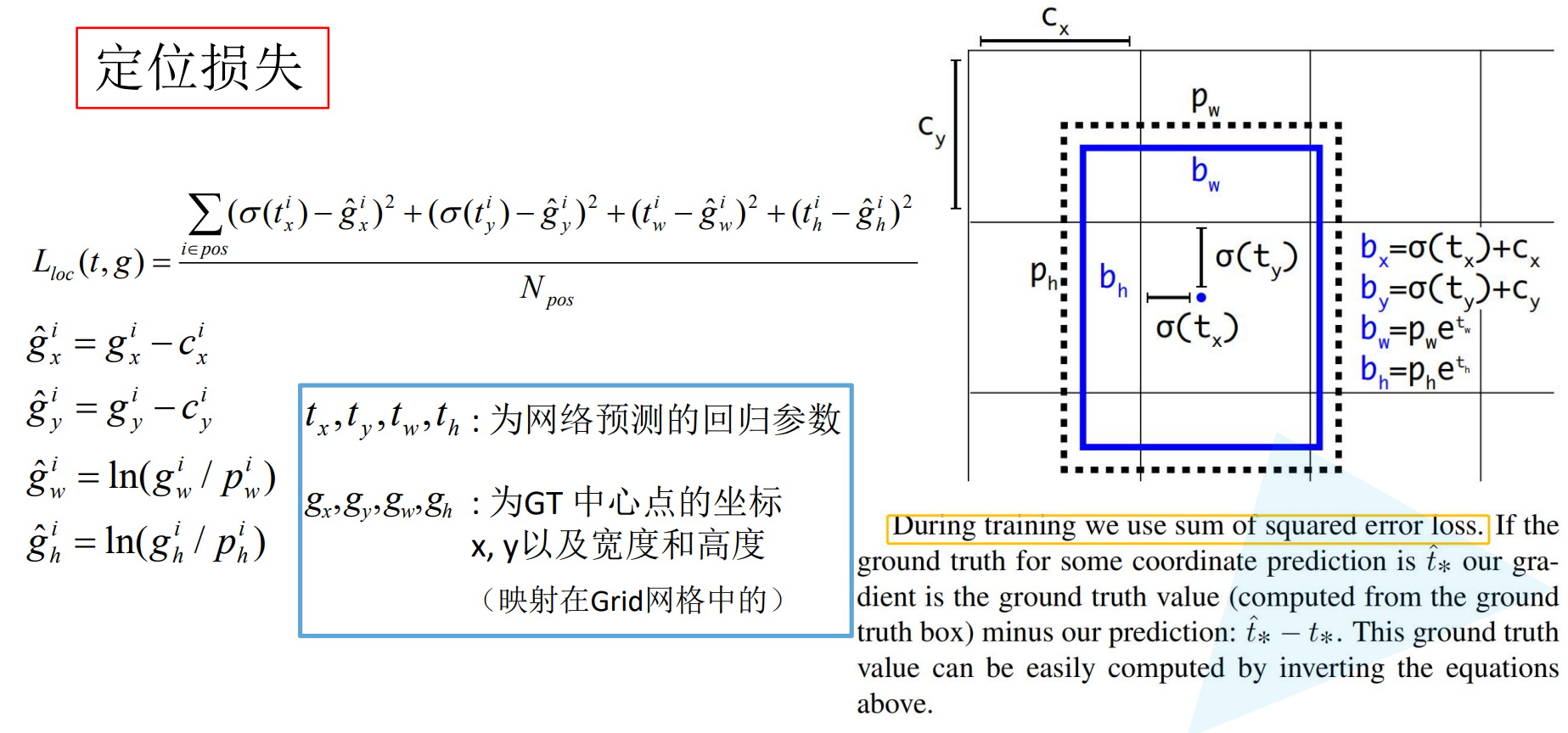
1.3 损失函数
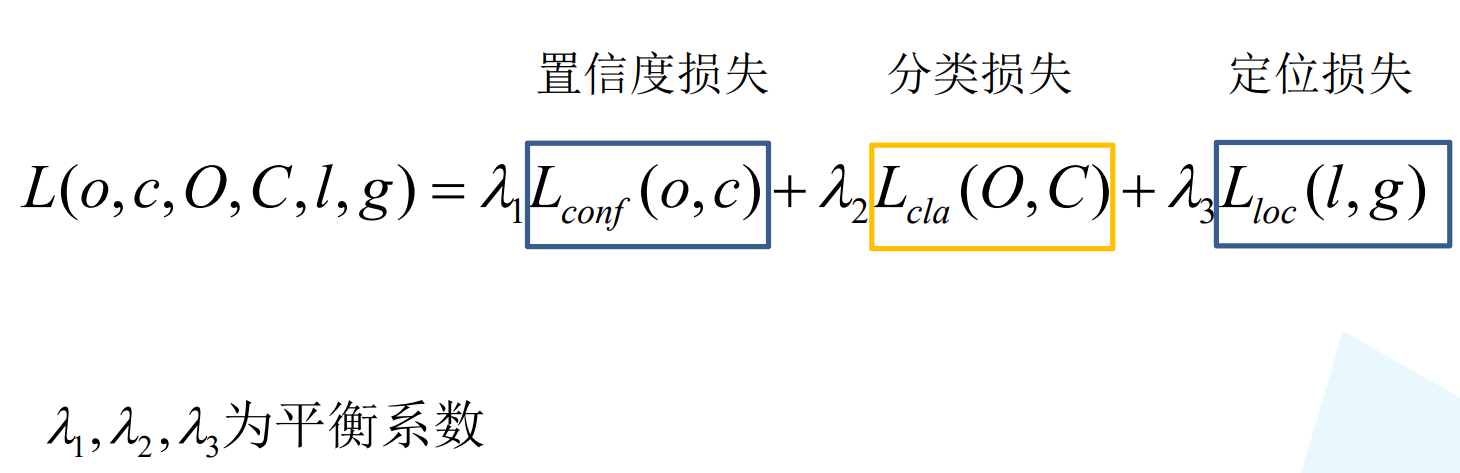
损失函数包含三大块,confidence损失,classes分类损失,bounding box损失
三个损失是环环相扣的,confidence损失判断是否存在目标物体,如果存在目标那么分类是否准确则依靠classes分类损失,最后检测框定位是否准确则依靠bounding box定位损失。

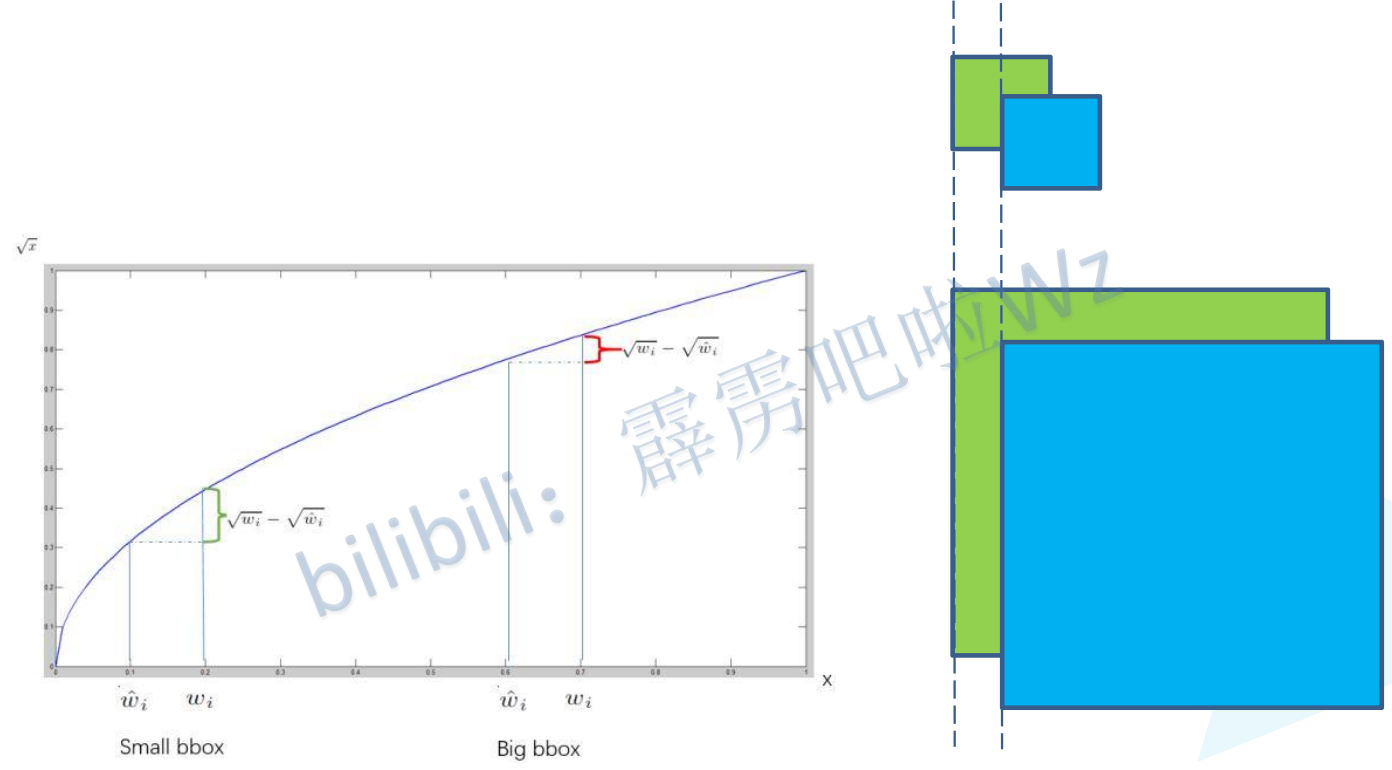
相同偏移不同尺度的bounding box理应有不同的损失量,因此对bounding box 的长宽开了根号,这样同样的偏移量在大尺度的检测框下损失会更小一些。
1.4 存在的不足
- YOLO的物体检测精度低于其他state-of-the-art的物体检测系统。
- YOLO容易产生物体的定位错误。
- YOLO对小物体的检测效果不好(尤其是密集的小物体,因为一个栅格只能预测2个物体)。
2. YOLOv2
YOLOv2相较于YOLOv1的主要改进有如下几点。
2.1 锚框卷积
相较于YOLOv1直接预测bbox的坐标,YOLOv2借鉴FastRCNN引入了anchor机制,不再直接预测anchor的坐标,转而对偏移量offset进行预测。对偏移量进行预测使得网络更加容易学习。
记得YOLOv1在最后有一个全连接层,这限制了YOLOv1输入图像的尺寸大小,于是在YOLOv2将全连接层去除,这使得YOLOv2的主干网络变成了一个全卷积网络,因此输入图像的大小不受限制。
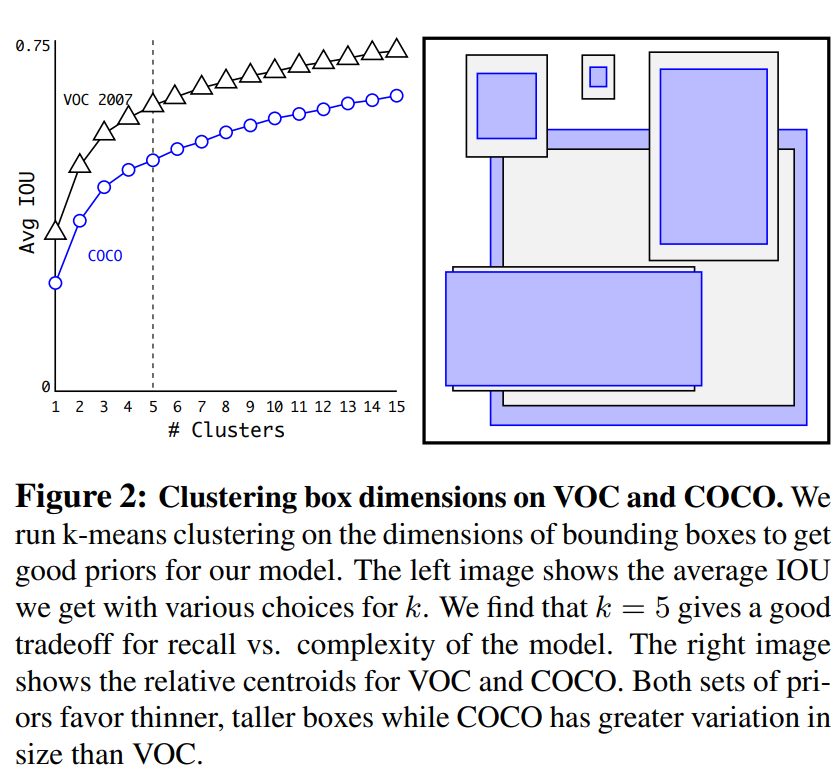
2.2 维度聚类
在FastRCNN中 ,会生成大量的anchor,而anchor的形状 都是通过手工设计的,在YOLOv2中,通过对标注的数据集所有目标的边界框进行k-means聚类来生成主要的anchor形状,根据聚类结果设置anchor。在YOLOv2中根据CoCo数据集聚类,绘制了平均IoU和聚类中心数量K之间的关系,该论文选择的是k=5。
2.3 直接定位预测
YOLOv2借鉴RPN网络使用Anchor boxes来预测边界框相对于先验框的offsets。边界框的实际中心位置(x,y)需要利用预测的坐标偏移值(t_x,t_y),先验框的尺度(w_a,h_a)以及中心坐标(x_a,y_a)来计算,这里的x_a和y_a也即是特征图每个位置的中心点:
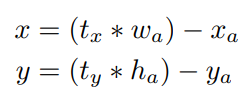
上面的公式也是Faster-RCNN中预测边界框的方式。但上面的预测方式是没有约束的,预测的边界框容易向任何方向偏移,因为t_x和t_y不受限制,导致每个位置预测的边界框可以落在图片的任意位置,这就导致模型训练的不稳定性,在训练的时候要花很长时间才可以得到正确的offsets。
YOLOv2弃用了这种预测方式,而是沿用YOLOv1的方法,就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看做1)。
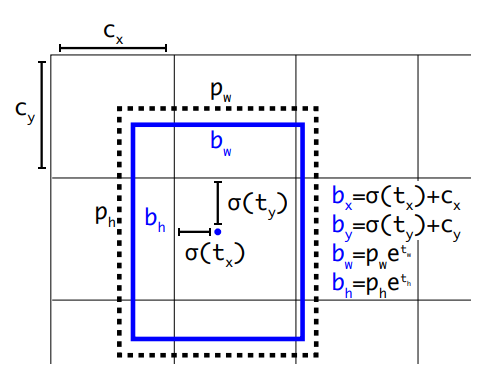
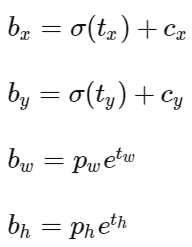
其中 (cx,xy)(cx,xy) 为cell的左上角坐标,如图所示,在计算时每个cell的尺度为1,所以当前cell的左上角坐标为 (1,1)(1,1) 。由于sigmoid函数的处理,边界框的中心位置会约束在当前cell内部,防止偏移过多。而 p_w 和 p_h是先验框的模板宽度与长度,前面说过它们的值也是相对于特征图大小的,在特征图中每个cell的长和宽均为1。这里记特征图的大小为 (W,H)(W,H) (在文中是 (13,13)(13,13) ),这样我们可以将边界框相对于整张图片的位置和大小计算出来(4个值均在0和1之间)
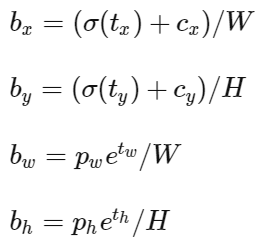
需要注意的是,上述四条公式计算的是相对整张图的位置,值仍然是0到1之间。
2.4 网络结构与细粒度特征
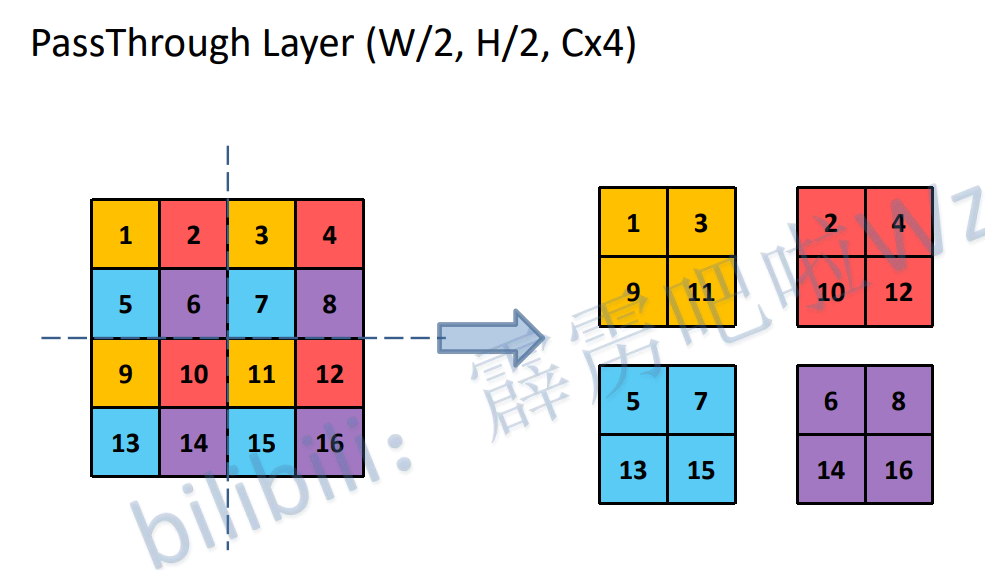
由于YOLOv1在检测小目标的任务上表现不理想。因为浅层特征图的感受野通常较小,因此浅层特征图往往保留了更多的细节信息,而深层特征图感受野比较大,因此深层特征往往代表了比较高层的抽象的特征,对应到原图上就是一些大范围偏向宏观的特征,而细节信息在传递到深层网络的时候容易产生损失,因此在原有基础上加入PathThrough Layer层,目的在于将浅层特征图保留的细节信息能够传递到深层特征图上,以此来提高YOLOv2的小目标检测能力。
PassThroughLayer操作示意图
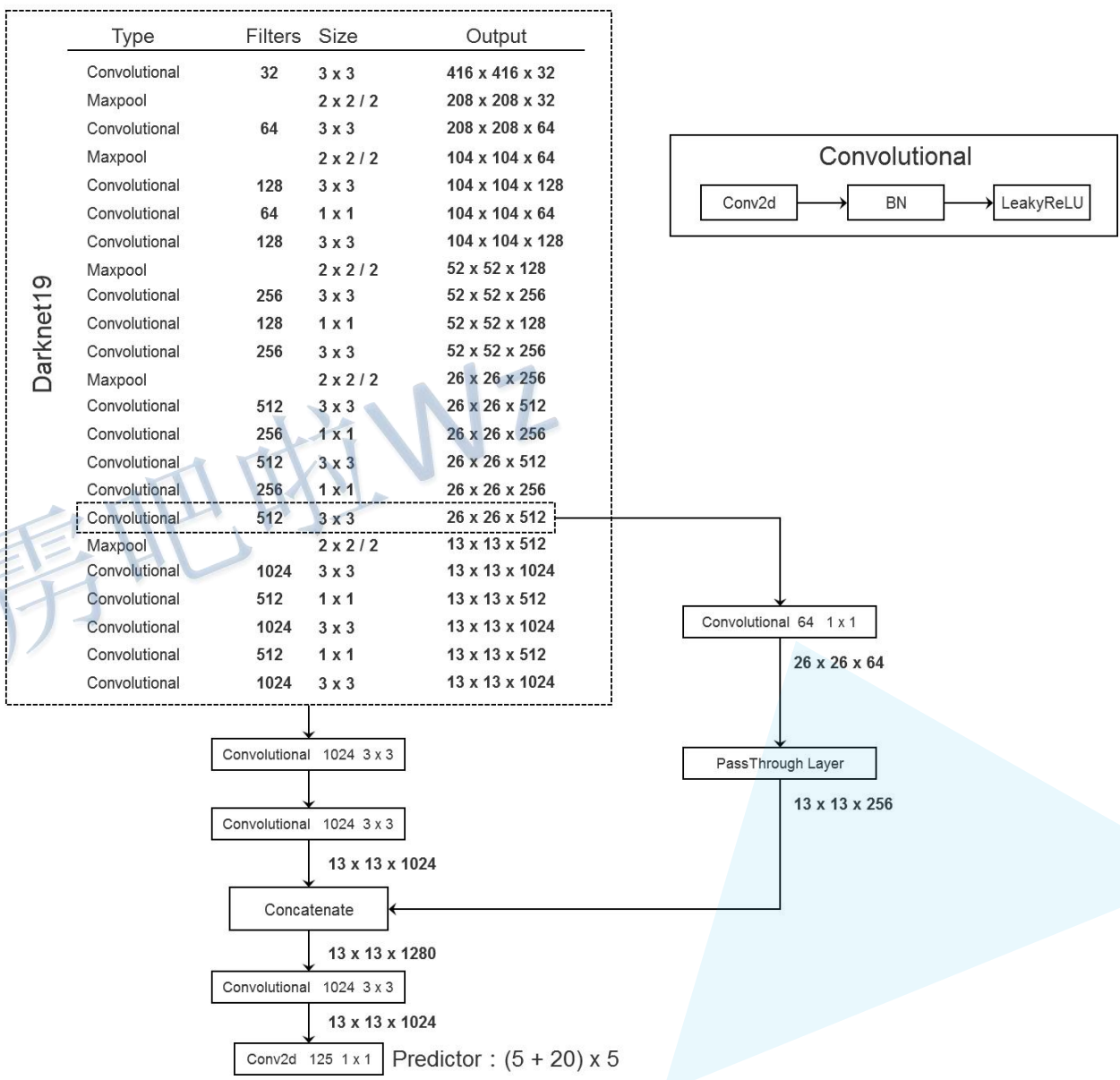
2.5 多尺度训练
得益于YOLOv2的全卷积结构,图像输入可以不用固定死尺寸,这使得YOLOv2能够利用多种尺度的图像数据进行训练,提高鲁棒性。
2.6 WordTree
用来混合数据集进行训练。
3. YOLOv3
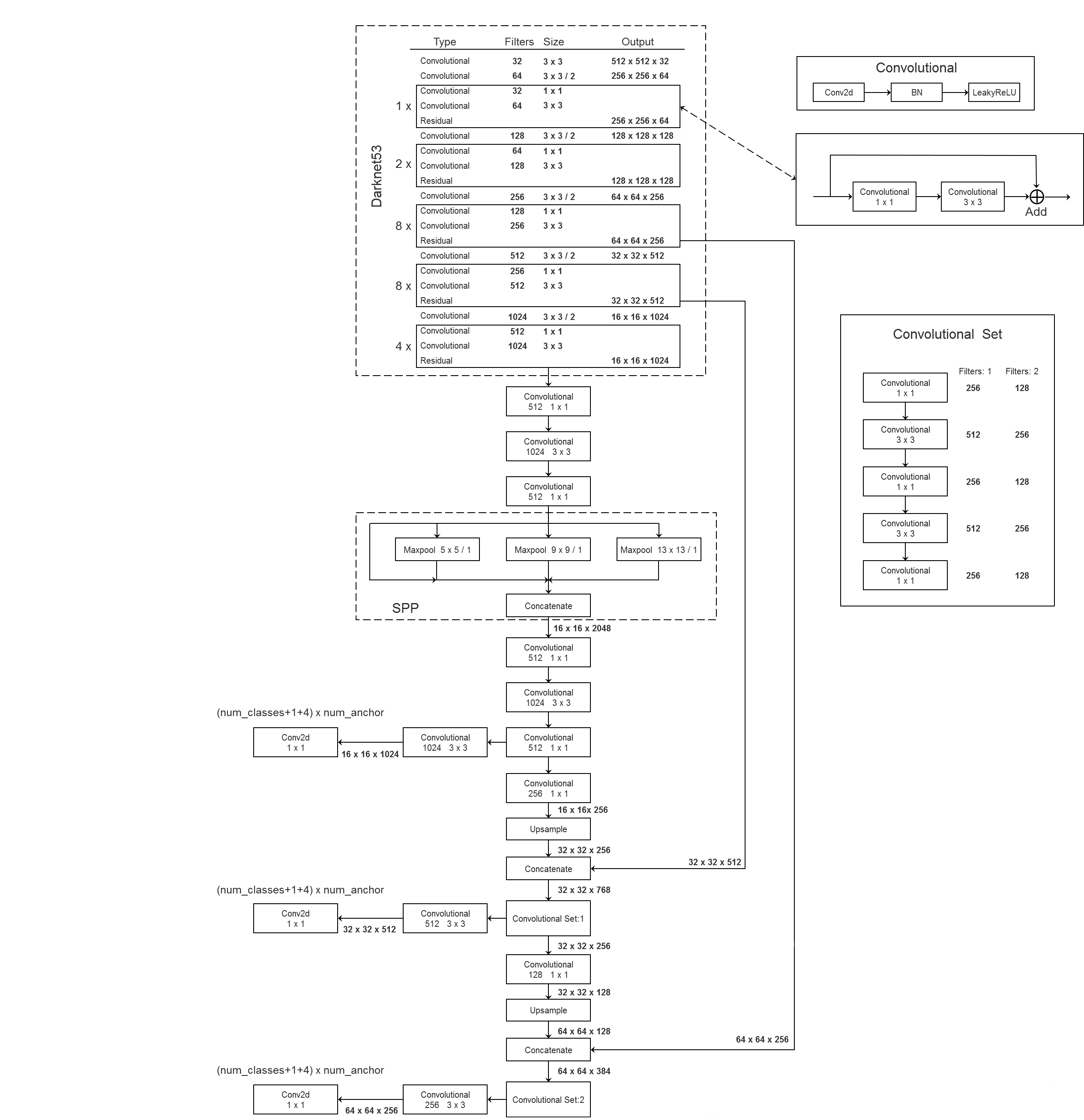
3.1 网络结构

YOLOv3通过k-means聚类k=9,将anchor分为了9种模板,9个不同尺度的anchor模板按照大小被分配给3个不同尺度的特征图,每个特征图对应3种尺度的anchor。单个预测框就包含5个参数[t_x,t_y,t_w,t_h,obj],CoCo数据集包含有80个类别,以最小的13x13特征层为例,输出tensor的形状就是13x13x[3*(4+1+80)]。
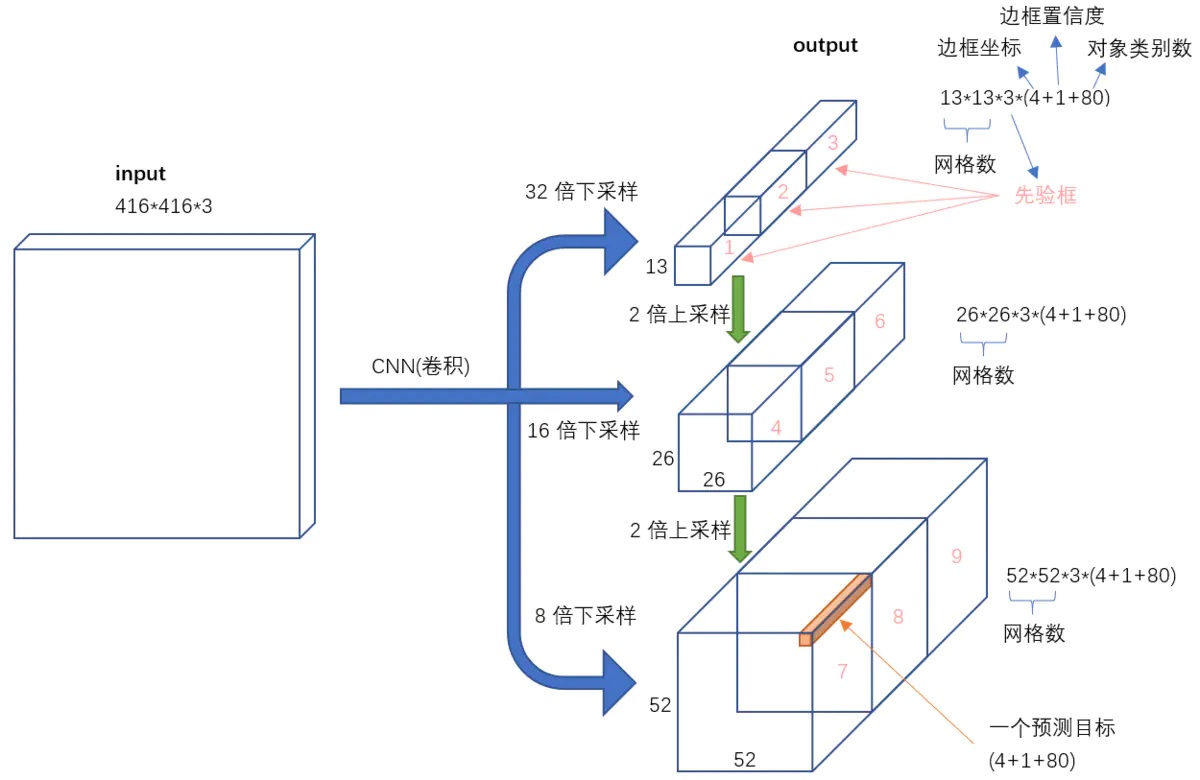
对于一个输入图像,YOLO3将其映射到3个尺度的输出张量,代表图像各个位置存在各种对象的概率。
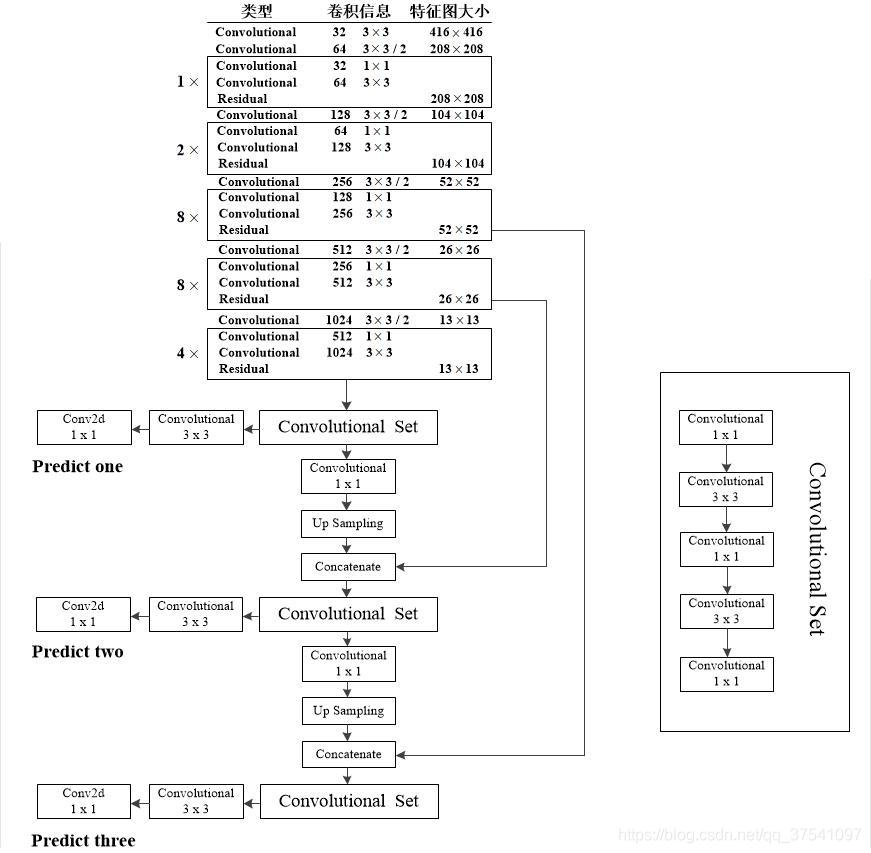
主干网络darknet53 去掉了maxpooling层,加入了残差块。
YOLOv3在通过主干网络darknet53之后,通过两次上采样来获得三个不同尺度的特征图,分别是13x13,26x26,52x52大小的特征图,13x13大小的特征图感受野大因此分配大尺度的anchor模板,具体模板尺寸和分配如下表所示。

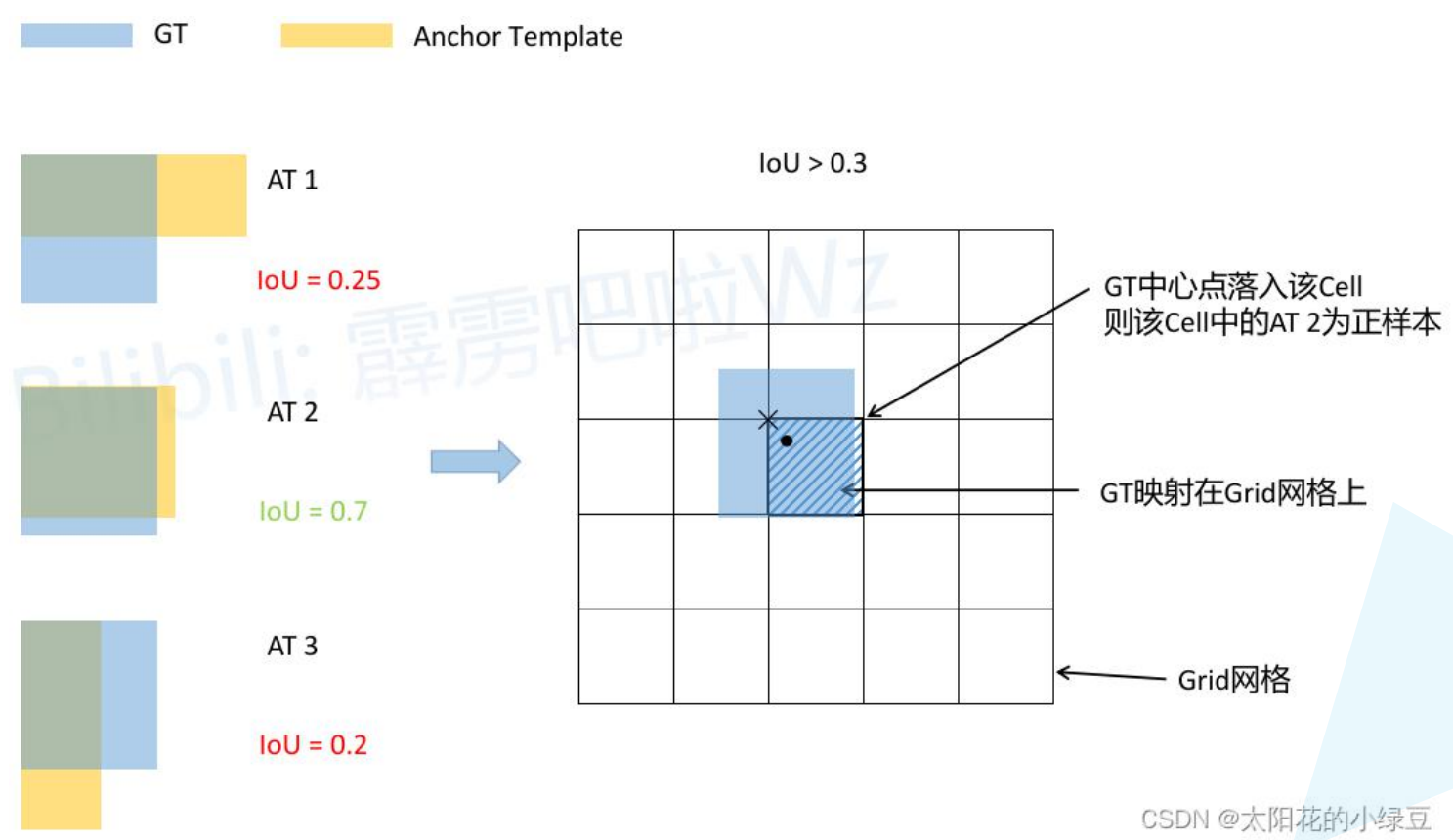
3.3 正负样本的选择
有别于原文,https://github.com/ultralytics/yolov5 版本的实现。



4. YOLOv3 spp
4.1 网络结构以及SPP模块
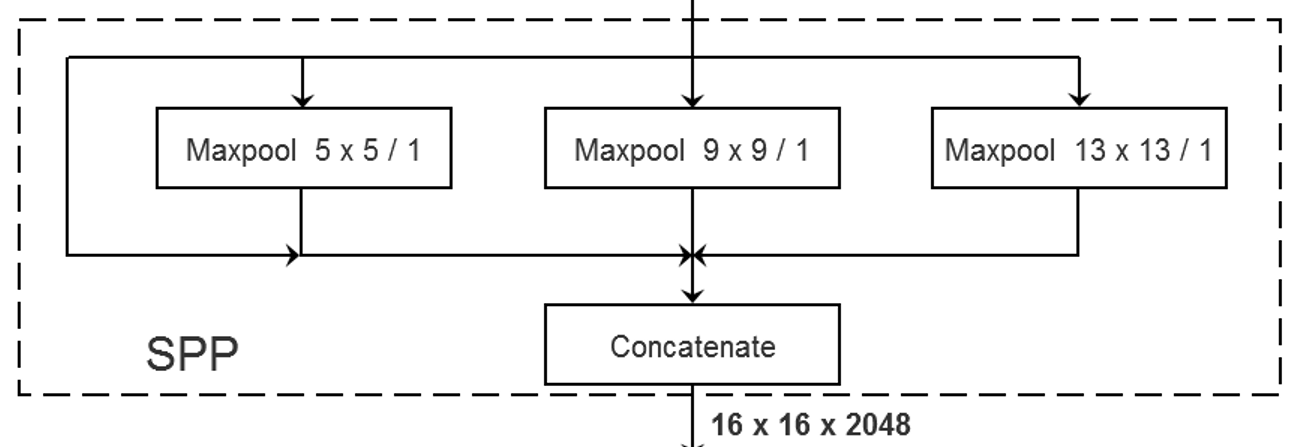
在maxpooling之前进行padding填充以保证池化之后特征图的长宽都不变,最后进行特征维度上的叠加,将不同尺度的特征图进行特征融合。
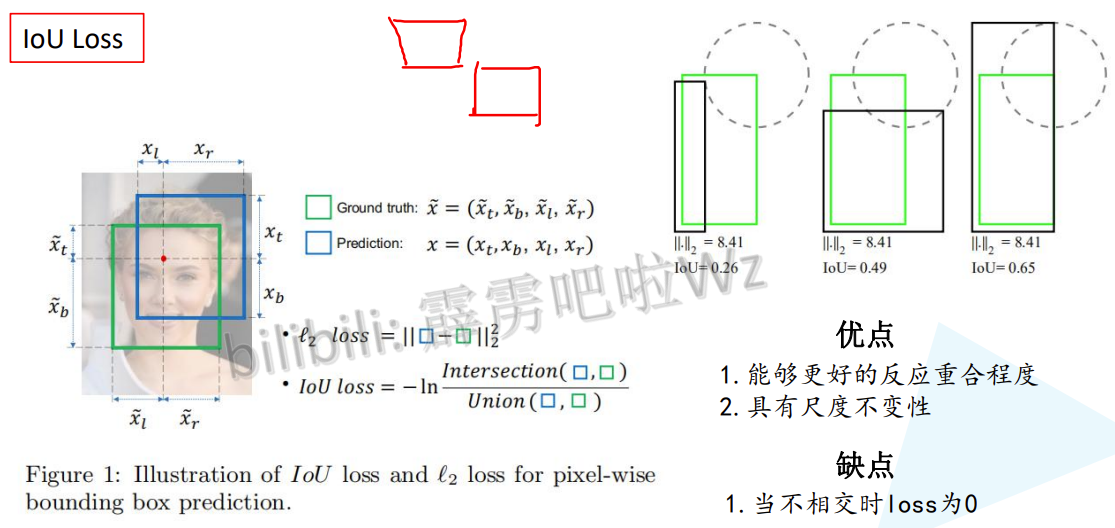
4.2 IoU Loss
4.3 GIoU Loss
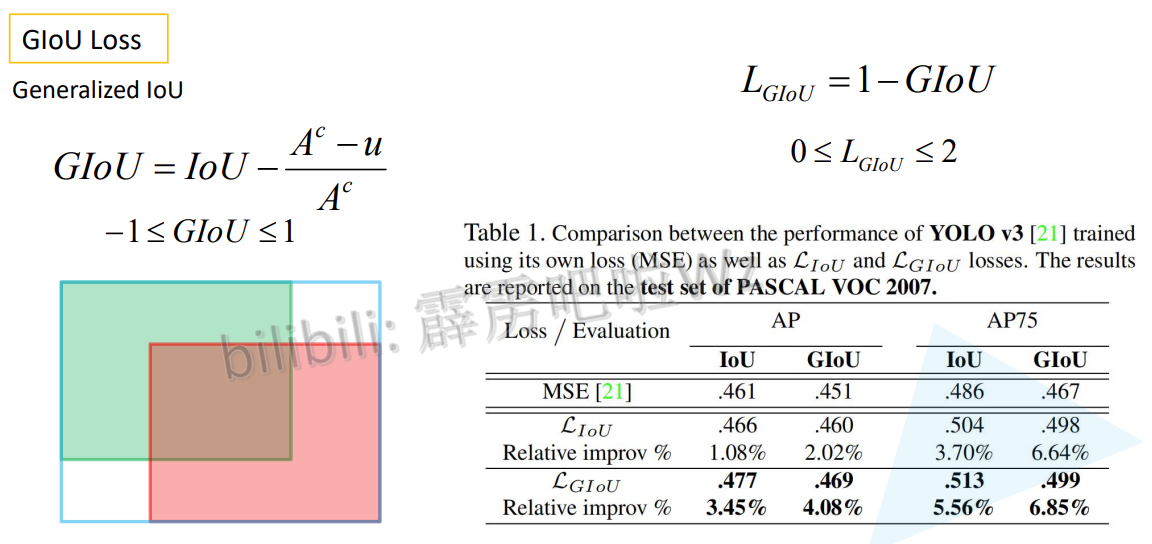
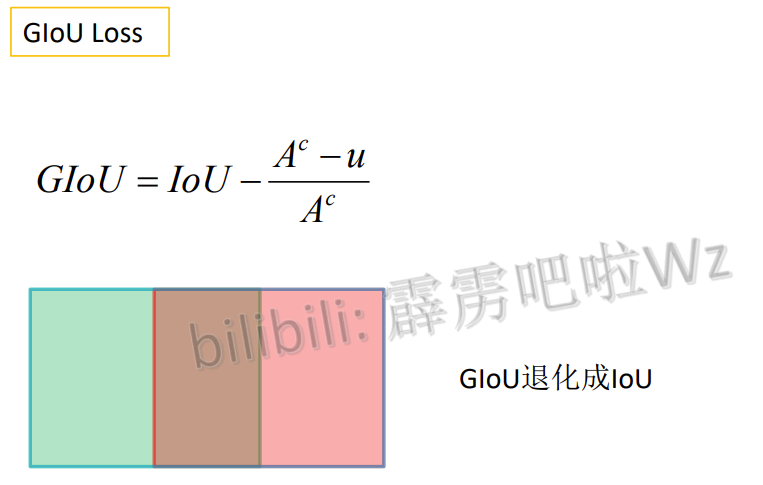
4.4 DIoU Loss
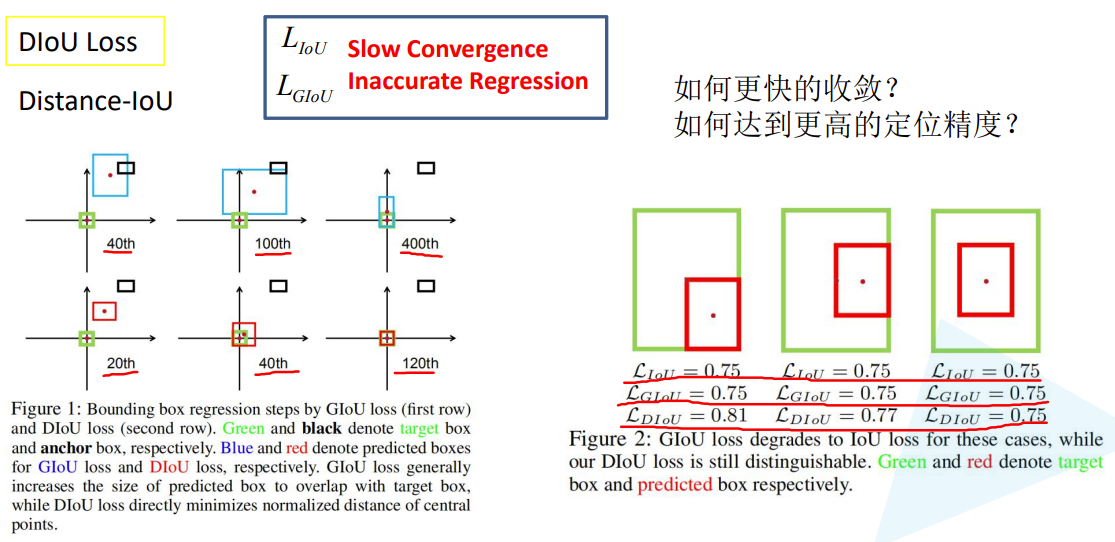

4.5 CIoU Loss

4.6 Focal Loss
p_t值越大说明分类情况越好,在正样本y=1的情况下,p_t=p,p值越大说明分类越好,负样本y=0的时候,p_t=1-p,此时p越小说明分类效果越好,不管哪种情况分类效果越好p_t的值就越大
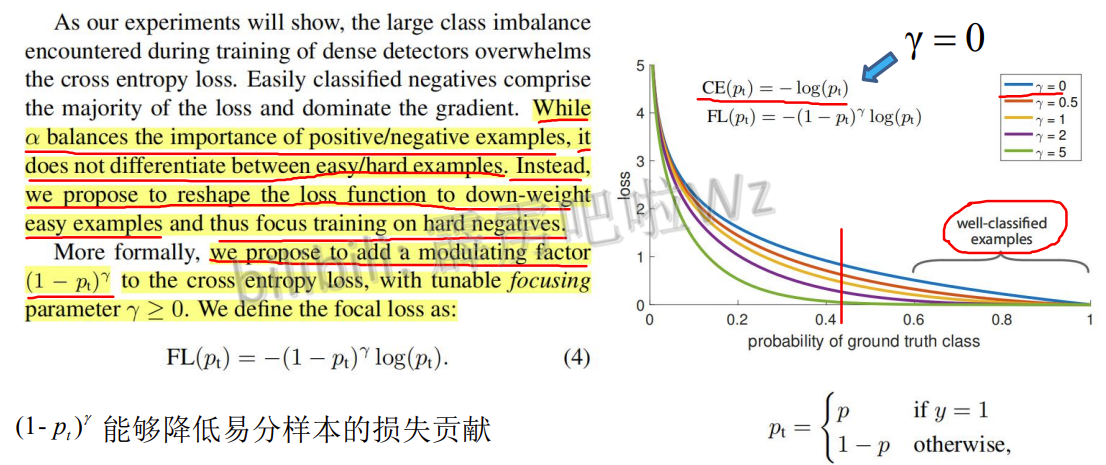
alpha-balanced focal-loss
提供了一个超参数alpha,