通道注意力机制以及3D卷积 1. SEnet
SENet的Block单元,图中的Ftr是传统的卷积结构,X和U是Ftr的输入(C’xH’xW’)和输出(CxHxW)。
SENet增加的部分是U后的结构:对U先做一个Global Average Pooling(图中的Fsq(.),作者称为Squeeze过程),输出的1x1xC数据再经过两级全连接(图中的Fex(.),作者称为Excitation过程),最后用sigmoid(论文中的self-gating mechanism)限制到[0,1]的范围,把这个值作为scale乘到U的C个通道上, 作为下一级的输入数据。这种结构的原理是想通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
Excitation部分是用2个全连接来实现 ,第一个全连接把C个通道压缩成了C/r个通道来降低计算量(后面跟了RELU),第二个全连接再恢复回C个通道(后面跟了Sigmoid),r是指压缩的比例。作者尝试了r在各种取值下的性能 ,最后得出结论r=16时整体性能和计算量最平衡。
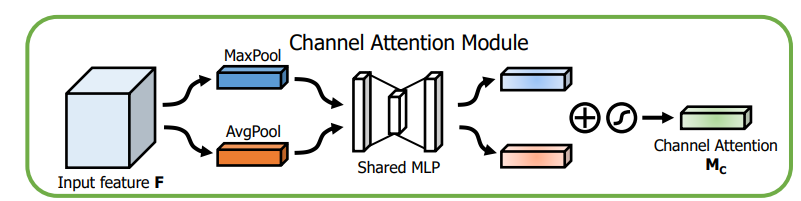
2. CBAM 2.1 CAM
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import torchfrom torch import nn class ChannelAttention (nn.Module): def __init__ (self, in_planes, ratio=16 ): super (ChannelAttention, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1 ) self.max_pool = nn.AdaptiveMaxPool2d(1 ) self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1 , bias=False ) self.relu1 = nn.ReLU() self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1 , bias=False ) self.sigmoid = nn.Sigmoid() def forward (self, x ): avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x)))) max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x)))) out = avg_out + max_out return self.sigmoid(out) if __name__ == '__main__' : CA = ChannelAttention(32 ) data_in = torch.randn(8 ,32 ,300 ,300 ) data_out = CA(data_in) print (data_in.shape) print (data_out.shape)
2.2 SAM
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import torchfrom torch import nnclass SpatialAttention (nn.Module): def __init__ (self, kernel_size=7 ): super (SpatialAttention, self).__init__() assert kernel_size in (3 , 7 ), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 self.conv1 = nn.Conv2d(2 , 1 , kernel_size, padding=padding, bias=False ) self.sigmoid = nn.Sigmoid() def forward (self, x ): avg_out = torch.mean(x, dim=1 , keepdim=True ) max_out, _ = torch.max (x, dim=1 , keepdim=True ) x = torch.cat([avg_out, max_out], dim=1 ) x = self.conv1(x) return self.sigmoid(x) if __name__ == '__main__' : SA = SpatialAttention(7 ) data_in = torch.randn(8 ,32 ,300 ,300 ) data_out = SA(data_in) print (data_in.shape) print (data_out.shape)
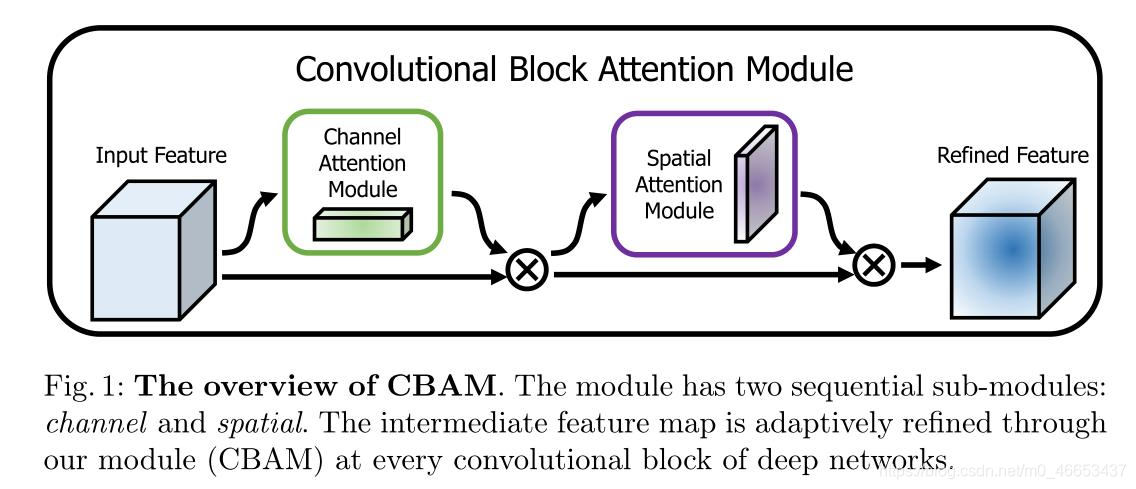
2.3 CBAM
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import torchfrom torch import nnclass ChannelAttention (nn.Module): def __init__ (self, in_planes, ratio=16 ): super (ChannelAttention, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1 ) self.max_pool = nn.AdaptiveMaxPool2d(1 ) self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1 , bias=False ) self.relu1 = nn.ReLU() self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1 , bias=False ) self.sigmoid = nn.Sigmoid() def forward (self, x ): avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x)))) max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x)))) out = avg_out + max_out return self.sigmoid(out) class SpatialAttention (nn.Module): def __init__ (self, kernel_size=7 ): super (SpatialAttention, self).__init__() assert kernel_size in (3 , 7 ), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 self.conv1 = nn.Conv2d(2 , 1 , kernel_size, padding=padding, bias=False ) self.sigmoid = nn.Sigmoid() def forward (self, x ): avg_out = torch.mean(x, dim=1 , keepdim=True ) max_out, _ = torch.max (x, dim=1 , keepdim=True ) x = torch.cat([avg_out, max_out], dim=1 ) x = self.conv1(x) return self.sigmoid(x) class CBAM (nn.Module): def __init__ (self, in_planes, ratio=16 , kernel_size=7 ): super (CBAM, self).__init__() self.ca = ChannelAttention(in_planes, ratio) self.sa = SpatialAttention(kernel_size) def forward (self, x ): out = x * self.ca(x) result = out * self.sa(out) return result if __name__ == '__main__' : print ('testing CBAM' .center(100 ,'-' )) torch.manual_seed(seed=20200910 ) cbam = CBAM(32 , 16 , 7 ) data_in = torch.randn(8 ,32 ,300 ,300 ) data_out = cbam(data_in) print (data_in.shape) print (data_out.shape)
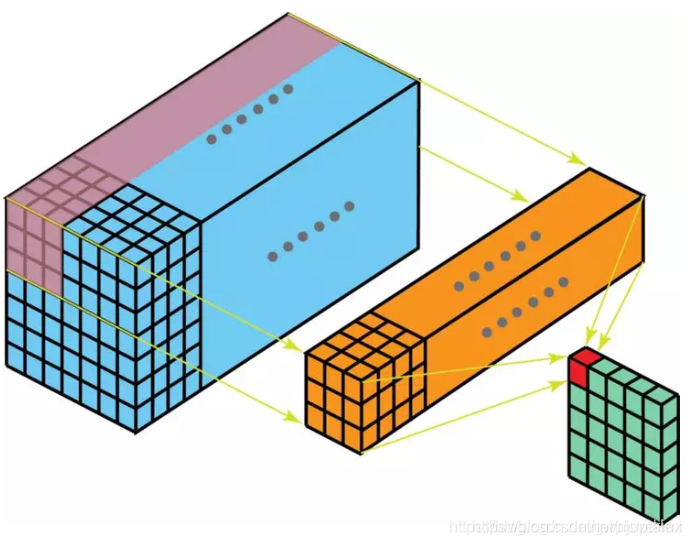
3. 3D卷积 3.1 2D卷积 常见的2D卷积。nn.Conv2d()。
下图展示了CxHxW 的输入特征,通过2D卷积层,得到1xHxW 的输出特征的过程
以上图为例,Conv2d卷积核的的尺寸是3x3xC
如果输出通道为K,则如下图所示,一共用了K个3x3xc 的卷积核,卷积层参数量为:Cx3x3xK
3.2 3D卷积 假设有一个视频序列,该视频的每一帧都是一张灰度图,只有一个通道,该视频一共有T帧,那么这一个视频可以用如下蓝色数据立方体表示。
以该灰度视频序列3D特征为例,做TxHxW 方向上的滑动3D卷积。该3x3x3 的3D卷积核,在三个方向上滑动得到的一个THW都更小的3D输出特征。
这种3D卷积我将按如下方式描述:
只有1组卷积核组,每组卷积核组中只有1个(灰度图通道数为1)3x3x3 的3D卷积核,卷积计算完得到1个绿色的feature map。
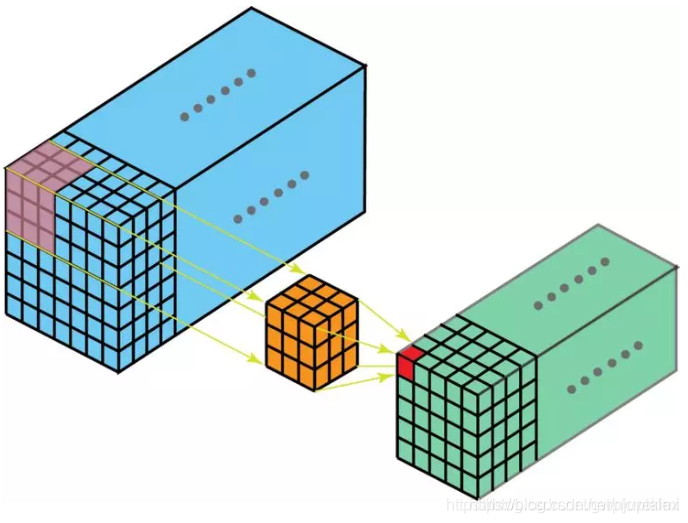
更复杂的情况,视频序列含有T帧图像,其中的每一帧不是灰度图,而是通道数为C的彩图,比如RGB图像C=3。
那么则可以将下图3D卷积按如下方式描述:
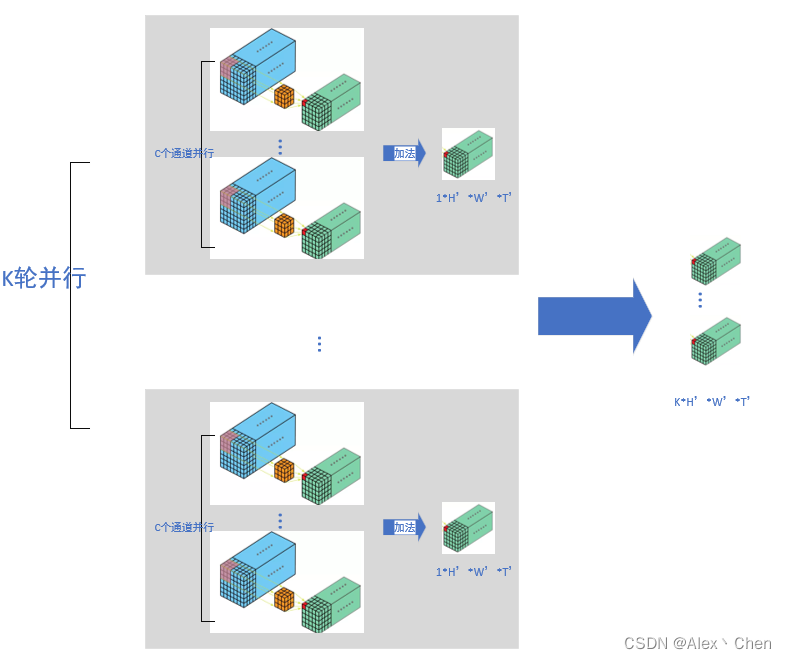
有K组卷积核组,每个卷积核组中有C个3x3x3 的3D卷积核。第i个卷积核组卷积得到1个绿色feature map,其中1<=i<=k。一共有K组,故生成K个绿色feature map。
对于任意1组卷积核组内,按照如下方式进行卷积计算,将1个通道的每一帧拼接构成一个蓝色立方体,一共有C个通道故有C个蓝色立方体,每个通道配备一个3x3x3 的卷积核进行卷积,则一共有C个3x3x3 的卷积核。组内C个卷积核与其对应的蓝色立方体进行卷积,得到C个小一号的绿色立方体,将这C个绿色立方体相加得到该组卷积核的输出。
因为一共有K组,所以将任意1组卷积核组的操作进行K次,得到K个绿色立方体feature map。综上,参数不相同的3x3x3 卷积核一共有CxK 个。
4. 参考链接 注意力机制(通道注意机制、空间注意力机制、CBAM、SELayer)敲代码的小风的博客-CSDN博客 通道注意力机制
一文教你搞懂2D卷积和3D卷积_littlepeni的博客-CSDN博客
一文搞定3D卷积_三维卷积过程_Alex丶Chen的博客-CSDN博客